

LanguageWare and the 1641 Depositions
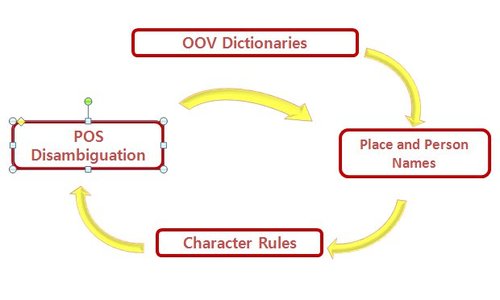
Building a model in LanguageWare is an iterative process involving the creation and the refinement of dictionaries, character rules, and parsing rules.
A series of parsing rules would ultimately be required to produce the required output, and constructing those was relatively simple. The difficulty was to provide LanguageWare with essential information about EME, so that the rules would produce useable output.
For our purposes, the most important thing was to ensure that verbs were identified reliably. To achieve this, the process outlined below was carried out iteratively. After each step, and after each iteration of the whole process, the accuracy of the output was evaluated.
Out of Vocabulary Dictionaries
Out of Vocabulary Dictionaries are a powerful means of extending LanguageWare’s capabilities. By adding words with regular ending patterns to the OOV dictionary LanguageWare can be trained to identify the part of speech for unknown words with similar endings. An OOV dictionary with the conjugations of a number of strong and weak EME verbs was created. This vastly increased the proportion of true positives. However, it concomitantly generated a very large number of false positives.
Place and Person Names
Since, by definition, OOV dictionaries are used by LanguageWare to identify the POS for unknown words, a high percentage of the false positives were proper nouns, especially surnames and place names which do not appear in LanguageWare’s built-in dictionaries.
Character Rules
Next we had to address the false negatives. These were added to a Character Rules dictionary. Character rules are primarily designed to allow the use of regular expressions to identify entities. However, they also proved a valuable way of tagging verbs. A separate set of character rules was created to control for variation in modal verbs.
POS Disambiguation
LanguageWare’s built-in part of speech tagger performs POS disambiguation. The accuracy of this was not as good as the project required. Therefore, a combination of character rules and dictionaries was used manually to disambiguate our results